지난 1편과 2편에 이어서 정렬-ORDER BY부터 이어서 작성해보려고 한다.
<정렬 -ORDER BY>
ORDER BY로 검색 결과 정렬하기
항상 정해진 순서로 결괏값을 얻기 위해서는 ORDER BY구를 지정해줘야한다.
SELECT 명령의 ORDER BY 구로 정렬하고 싶은 열을 지정한다.
지정된 열의 값에 따라 행 순서가 변경된다.
이때 ORDER BY 구는 WHERE 구 뒤에 지정한다.
SELECT 열명 FROM 테이블명 WHERE 조건식 ORDER BY 열명;
검색 조건이 필요없는 경우에는 WHERE 구를 생략하는데 이때 ORDER BY구는 FROM 구 뒤에 지정한다.
SELECT 열명 FROM 테이블명 ORDER BY 열명
만약 테이블에서 age라는 컬럼에 값을 뽑을 때 오름차순으로 정렬해서 뽑고 싶다면
SELECT * FROM 테이블명 ORDER BY age; 라고 작성해주면된다.
그렇게 되면 작은수가 위에서부터 아래로 내려가면서 큰 수가 나오는 형태로 데이터를 뽑을 수 있게 된다.
기본적으로 오름차순으로 정렬되게 되어있어서 값이 작은 수 부터 큰 수로 오름차순으로 출력된다.
ASC가 오름차순으로 기본 디폴트로 되어있어서 생략이 가능하다.
숫자가 아닌 문자같은 경우 ABCD...순으로 나오게 된다.
그래서 예를 들어 대구, 부산, 서울 이라는 값을 address라는 필드에서 디폴트 ASC로 정렬해서 데이터를 뽑게되면
SELECT * FROM 테이블명 ORDER BY address; 라고 적어주면
대구
부산
서울
가나다라마바사아자카.. 순으로 대구가 먼저나오고 그 다음 부산 마지막으로 서울이 출력되게 된다.
ORDER BY DESC로 내림차순으로 정렬하기
그렇다면 오름차순이 아닌 내림차순으로 정렬을 해보자
SELECT 열명 FROM 테이블명 ORDER BY 열명 DESC;
앞선 예제에서 아무것도 지정하지 않았는데 오름차순으로 정렬되었다. 오름차순은 생략하면 자동으로 오름차순이 부여되지만
내림차순은 꼭 작성해줘야한다.
DESC는 descendant(하강), ASC는 ascendant(상승)의 약자이다.
DESC, ASC 모두 ↓ 출력흐름은 위에서 부터 아래로 나오게 됨
DESC
ㅁㅁㅁㅁㅁㅁ(큰값부터 아래로 갈 수록 작아짐)
ㅁㅁㅁㅁ
ㅁㅁ
ㅁ
ASC
ㅁ(작은값부터 시작해서 아래로 갈 수록 커짐)
ㅁㅁ
ㅁㅁㅁ
ㅁㅁㅁㅁ
ㅁㅁㅁㅁㅁ
결론적으로 지정을 따로 하지 않으면 ORDER BY의 기본 정렬방법은 오름차순이다.
대소관계
ORDER BY로 정렬할 때 값의 대소관계가 중요하다. 수치형 데이터라면 대소관계는 숫자의 크기로 판별하므로 이해하기 쉽다.
날짜시간형 데이터도 수치형 데이터와 마찬가지로 숫자 크기로 판별한다.
1999년<2013년<2022년 ... < ...
문제는 문자열형 데이터이다. 이때 알파벳이나 한글 자모음 배열 순서로 사용하여 문자를 차례대로 나열하는데
예를 들어 '나비', '가방', '가족' 이렇게 3개를 정렬한다고 하면
순서는
1. 가방
2. 가족
3. 나비
이렇게 나온다.
제일먼저 첫번째 가,가,나 를 기준으로
가방 가족 둘을 먼저 정렬하고 가나다순에서 다음 순서인 나 를 가지고 있는 나비가 오게되는데
가방과 가족은 앞에가 동일하기 때문에 이럴 경우 뒤에있는 방과 족을 비교해서 순서를 정한다.
그렇게 되서 'ㅂ'이 'ㅈ'보다 사전식에서 우선이기때문에 가방>가족>나비 이렇게 나오게 되는 것이다.
문자열형 데이터의 대소관계는 이처럼 '사전식 순서'에 의해 결정된다.
그런데 이렇게되면 대체 뭐가 문제일까? 아무런 문제가 없어보이는데??
사전식 순서에서 주의할 점
예를 들어
SELECT * FROM 테이블명;
이렇게 조회를 때렸을 때
2개의 필드가 출력된다고 해보자
필드명a 필드명b
1 1
2 2
10 10
11 11
이렇게 있다고 했을 때
a열이 문자열형(VARCHAR)
b열이 수치형(INTEGER)로 이루어진 테이블이라고 했을 때
각 행의 열은 서로 동일한 값으로 지정되어 있다.
여기서 a열을 오름차순으로 정렬해보자.
SELECT * FROM 테이블명; ORDER BY a;
필드명a 필드명b
1 1
10 2
11 10
2 11
이상하다 DESC를 적지도않았고 기본 정렬 값인 ASC로 되어있는데 왜 값이 1,2,10,11이 아닐까?
1보다 2가 큰 것은 당연한데?
문제의 원인은 필드명a는 타입이 VARCHAR로 되어있어서 문자열로 인식이되서
대소관계를 판단할 때 수치형이 아닌 사전식 순서로 판단했기 때문이다.
이 상태에서 만약
SELECT * FROM 테이블명; ORDER BY b; 라고 작성했다면
1
2
10
11
이렇게 순서대로 잘 나왔을 것이다.
문자열형 열에도 숫자 데이터를 넣을 수 있다.
숫자도 문자의 일종이므로 저장하는데 아무런 문제가 되지 않는다.
하지만 문자열형에 숫자를 저장하면 문자로 인식되어 대소관계의 계산 방법이 달라진다.
정렬이나 비교연산을 할 때에는 이 점에 꼭 주의해야 한다.
ORDER BY는 테이블에 영향을 주지 않는다.
ORDER BY를 이용해 행 순서를 바꿀 수 있다. 하지만 이는 어디까지나 서버에서 클라이언트로
행 순서를 바꾸어 결과를 반환했을 뿐 저장장치에 저장된 데이터의 행 순서를 변경하는 것은 아니다.
SELECT는 데이터를 검색하는 명령어이다. 이는 테이블의 데이터를 참조만 할 뿐이며 변경은 하지 않는다.
복수의 열을 지정해 정렬하기
간단한 정렬을 ORDER BY 구로 해봤는데 이번에는 조금 더 복잡하게
복수 열을 지정해 정렬하는 방법에 관해 알아보자
SELECT 열명 FROM 테이블명 WHERE 조건식 ORDER BY 열명1 [ASC|DESC], 열명2[ASC|DESC]...
데이터 양이 많을 경우 하나의 열만으로는 행을 특정짓기 어려운 때가 많다.
예를들어 상품코드와 해당 상품의 하위코드까지 함께 고려했을 때 비로소 하나의 행을 특정 지울 수 있는
명세서 등을 들 수 있는데 이런 경우 복수의 열을 지정해 정렬하면 편리하다.
한편 정렬 시에는 NULL 값에 주의할 필요가 있다. 이 절의 마지막에 ORDER BY에서의 NULL값의 정렬 순서에 관래 다뤄보자.
복수 열로 정렬 지정
만약 ORDER BY로 정렬하는 경우 같은 값을 가진 행의 순서는 어떻게 정해지는 걸까?
또 ORDER BY 구는 생략할 수 있는데 이때 순서는 어떻게 정해질까?
답은 '순서는 일정하지 않다.' 이다. 데이터베이스는 서버의 당시 상황에 따라 어떤 순서로 행을 반환할지 결정한다.
따라서 언제나 같은 순서로 결과를 얻고 싶다면 반드시 ORDER BY 구로 순서를 지정해야 한다.
하지만 ORDER BY 구로 지정을 해도 1개의 열만으로 정확히 순서를 결정할 수 없는 경우가 있다.
같은 값을 가지고있을 경우가 그런 상황이다.
만약 2개의 필드가 있다고 해보자
필드명a 필드명b
1 1
2 1
2 2
1 3
1 2
이렇게 있다고 했을 때 두 필드 모두 INTEGER 타입이라고 해보자
열에는 1이나 2와 같은 값이 들어가 있다.
b열은 a열의 하위 번호이다.
이를 1-1 , 1-2, 1-3 ... 이런식으로 열의 상관관계에 맞춰 정렬하려고 한다.
SELECT 명령에는 ORDER BY가 있으니 이를 이용해서 a열로 정렬하면 원하는 결과를 얻을 수 있을 것이다.
SELECT * FROM 테이블명 ORDER BY a;
필드명a 필드명b
1 1
1 3
1 2
2 1
2 2
그 결과 a열은 제대로 1,2 순서대로 정렬되었다. 하지만 b열의 정렬 순서가
일정하지 않다. a열의 값이 1인 행이 총 3개가 있는데 서로 똑같아 순서를 결정할 수 없기 때문이다.
ORDER BY로 복수 열 지정하기
ORDER BY 구에는 복수로 열을 지정할 수 있다. SELECT 구에서 열을 지정한 것 처럼 콤마(,)로 열명을 구분해 지정하면 된다.
SELECT 열명 FROM 테이블명 ORDER BY 열명1, 열명2 ...
복수 열을 지정하면 정렬 결과가 바뀐다.
정렬 순서는 지정한 열명의 순서를 따른다.
이때 값이 같아 순서를 결정할 수 없는 경우에는 다음으로 지정한 열명을 기준으로 정렬하게 된다.
그렇다면 다시 기존에 정렬을 복수 열로 지정해서 해보자!
SELECT * FROM 테이블명 ORDER BY a, b;
a열로 먼저 정렬하고, 값이 같은 부분은 b열로 정렬한다. 그렇게하면 b열이 1, 3, 2로 바르게 정렬되지 않던 문제를 해결할 수 있다.
SELECT * FROM 테이블명 ORDER BY a, b;
필드명a 필드명b
1 1
1 2
1 3
2 1
2 2
이렇게 보면 a열은 순서대로 정렬하고 b열도 정렬을 했다.
다음으로 ORDER BY b,a와 같이 열 지정 순서를 바꾸면 어떻게 되는지 알아보자
SELECT * FROM testsql ORDER BY b,a;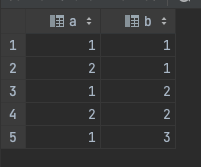
지금보면 b열은 순서대로
1
1
2
2
3
이렇게 크기순으로 정렬되었지만
a열은
1
2
1
2
1
이런식으로 값이 같은 부분은 a열로 정렬된 것을 볼 수 있다.
정렬방법 지정하기
복수열을 지정한 경우에도 각 열에 대해 개별적으로 정렬 방법을 지정 할 수 있다.
이때는 각 열 뒤에 ASC나 DESC를 붙여준다.
SELECT * FROM testsql ORDER BY a ASC, b DESC;이렇게 작성하고 출력해보면

이렇게 a열은 오름차순으로 나오고
b열은 내림차순으로 잘 나오고 있다.
여기를 잠깐 짚고 넘어가자면 이 부분에서 조금 햇깔렸던 것이 있는데
내가 정렬방법에 대해 잘못알고 있어서
왜 a가 11122 이런식으로 작은수가 다 나오고 그 다음 큰 수로 넘어가는데
b는 32211이 아니라 321 21이 나오지? 라고 생각했었다.
예를 들어

이렇게 데이터를 넣었다고 하면
a열 1번을 보면 a는 1 b는 3 으로 한 줄이 하나의 세트로 되어있다
1번줄에있는 a따로 b따로 1번이 아닌 3번 5번 10번으로 옮겨갈 수 없는 것이다.
그래서 이 데이터를 정렬을 해보면
SELECT * FROM testsql ORDER BY a ASC, b DESC;
이렇게 했을 경우

이렇게 출력이 되는데 나는 처음에
a열은 1~4까지 작은수부터 큰 수로 차곡차곡 정렬되는데
b열은 왜 3322111221131이런식으로 큰수 작은수 큰수 작은수 제멋대로 들어가지? 라는 생각을 했다.
알고보니 책에는 부연설명이 없었는데 너무 간단한거라서 설명을 안해줬나..? 라는 생각이 들었던게
만약 데이터를
insert into TESTSQL (a,b) values (1,3);
insert into TESTSQL (a,b) values (1,2);
insert into TESTSQL (a,b) values (1,1);
insert into TESTSQL (a,b) values (2,2);
insert into TESTSQL (a,b) values (2,1);
insert into TESTSQL (a,b) values (1,1);
insert into TESTSQL (a,b) values (1,2);
insert into TESTSQL (a,b) values (2,2);
insert into TESTSQL (a,b) values (1,1);
insert into TESTSQL (a,b) values (4,3);이렇게 넣었다고 가정하면
저 쿼리 각 줄은 하나의 세트로 들어가는 것이다
첫번째 줄에 1,3을 넣었다고 하고 1번글이라고 해보자
1번글에 있는 a컬럼 값 1, b컬럼 값 3이 각자 따로 돌아다닐 수는 없다.
a컬럼 값1이 1번글인데 3번글로 넘어가거나 5번글로 이동할 수 없다는 것이다.
결국에는 하나의 세트로 넘어가니까
a는 오름차순 b는 내림차순으로 복수정렬을 했는데
a는에서 가장 작은수 1과 b에서 가장 큰 수 3을 기준으로
순서대로 뽑는다
그래서 a컬럼에 가장 낮은수 1이 끝날때까지
a는 오름차순으로 1이 쭈욱나오고 그 a의 세트인 b는 내림차순이지만
a와 같은 행에 있기 때문에 데이터에 3은 총 3개 이지만
333 으로 나오지못하고 3322....이후에 끝에 3이 나오게된다.
그 이유는 a와 b는 하나의 세트이기 때문이다.
그래서
뒤에나오는 b컬럼 3의 세트인 a의 값은 4 이기때문에
a에서 오름차순으로 뽑을때 1나오고 2나오고 3나오고 4가 나올때가 되어서야
b컬럼에서도 내림차순으로 3이라는 숫자를 가져올 수 있게 되는 것이다.
그러니까 a순서가 1부터4까지 끝나지 않으면 b컬럼은 대기해야하는 것이다.
NULL 값의 정렬순서
ORDER BY로 정렬하는 법에 대해서 알아봤다. 지금부터는 NULL값이 저장된 열의 정렬방법을 살펴보자
기존에 언급했던 대소비교를 NULL값에는 할 수 없어서 별도의 방법이 필요하다.
별도의 방법으로는 '특정 값보다 큰 값' '특정 값보다 작은 값'의 두 가지로 나뉘며 이 중 하나의 방법으로 대소를 비교한다.
간단히 말하자면 ORDER BY로 지정한 열에서 NULL의 값을 가지는 행은 가장 먼저 표시되거나 가장 나중에 표시된다.
표준 SQL에서도 대소비교 방법에 NULL에 대한 기준을 따로 내려두지 않아서 제품군에 따라 비교 방법 기준이 조금씩 다르다.
MySQL의 경우에는 NULL 값을 가장 작은 값으로 취급해 ASC(오름차순)에서는 가장 먼저, DESC(내림차순)에서는 가장 나중에 표시한다.
결과 행 제한하기 - LIMIT
SELECT 명령에서는 결괏값으로 반환되는 행을 제한할 수 있다. LIMIT 구로 결과 행을 제한하는 방법에 대해 알아보자
SELECT 열명 FROM 테이블명 LIMIT 행수 OFFSET 시작행;
인터넷 쇼핑몰에서 물건을 구매하거나 커뮤니티 사이트의 게시판을 읽다 보면,
수많은 상품과 게시물을 전부 하나의 페이지에 표시하는 대신 몇 건씩 나누어 표시하는 것을 볼 수 있다.
이런 경우에 LIMIT 구를 사용해 표실할 건(행) 수를 제한할 수 있다.
행수 제한
LIMIT 구는 표준 SQL은 안디ㅏ. MySQL과 PostgreSQL에서 사용할 수 있는 문법이라는 점에 주의해야한다.
LIMIT 구는 SELECT 명령의 마지막에 지정하는 것으로 WHERE 구나 ORDER BY 구의 뒤에 지정한다.
SELECT 열명 FROM 테이블명 WHERE 조건식 ORDER BY 열명 LIMIT 행수
LIMIT 다음에는 최대 행수를 수치로 지정한다. 만약 LIMI 10으로 지정하면 최대 10개의 행이 클라이언트로 반환된다.
그럼 테이블을 이용해서 확인해보자
SELECT * FROM testsql;

모든 데이터를 출력해봤다.
여기서 3개의 행만 출력해보자
SELECT * FROM testsql LIMIT 3;

이렇게 1~3 까지의 행만 출력했다.
LIMIT으로 지정하는 것은 '최대 행수' 이다.
만약 테이블에 하나의 행만 있다면 LIMIT3으로 지정해도 1개의 행이 반환된다.
정렬한 후 제한하기
앞의 실습을 통해 LIMIT3으로 데이터를 뽑아낸 것과 동일한 결과를 얻기 위해서 WHERE구에 조건을 지정할 수도 있다.
예를 들면 WHERE a <=3 이런식으로 조건을 붙이면 동일한 결과를 뽑아 낼 수 있지만 LIMIT이랑 WHERE의 기능은
내부처리 순서가 전혀 다르다. LIMIT은 반환할 행수를 제한하는 기능으로, WHERE 구로 검색한 후 ORDER BY로 정렬된 뒤 최종적으로 처리된다. 그럼 이를 확인해보도록 하자. 먼저 a라는 열을 내림차순으로 정렬한 뒤 상위 3건만 조회하도록 해보자.
SELECT * FROM testsql ORDER BY a DESC LIMIT 3;

열이 2개라서 2개가 보이지만 현재는 정렬만 한 것이니까 a 컬럼에 집중해서 보자
현재 내림차순으로 4 4 3 순서로 출력이 되었고 1번부터 3번까지의 행만 출력되었다.
LIMIT을 사용할 수 없는 데이터베이스에서의 행 제한
아까 설명했던 것 처럼 LIMIT은 표준 SQL이 아니기 때문에 MySQL과 PostgreSQL 이외에 데이터베이스에서는 사용 할 수 없다.
SQL Server에서는 LIMIT와 비슷한 기능을 하는 'TOP'을 사용할 수 있다. 다음과 같이 TOP 뒤에 최대 행수를 지정하면 된다.
SELECT TOP 3 * FROM testsql;
Oracle에는 LIMIT도 TOP도 없다. 대신 ROWNUM이라는 열을 사용해 WHERE 구로 조건을 지정해서 행을 제한 할 수 있다.
SELECT * FROM testsql WHERE ROWNUM <= 3;
ROWNUM은 클라이언트에게 결과가 반환될 때 각 행에 할당되는 행 번호이다.
단, ROWNUM은 행을 제한 할 때는 WHERE 구로 지정하므로 정렬하기 전에 처리되어 LIMIT으로 행을 제한한 경우와 결괏값은 다르다.
이 문제에 관해서는 FROM 서브쿼리 사용하는 내용에서 다시 다뤄볼 생각이다.
오프셋 지정
웹시스템에서는 클라이언트의 블라우저를 통해 페이지 단위로 화면에 표시할 내용을 처리한다.
대량의 데이터를 하나의 페이지에 표시하는 것은 기능적으로도 속도 측면에서도 효율적이지 못하므로 일반적으로 페이징 처리를 한다.
커뮤니티같은 사이트에서 게시판 하단 부분에 보통 1 2 3 4 5 다음 으로 나오는 것이 페이징처리를 한 것인데
이 페이징 기능은 LIMIT을 사용해 간단히 구현할 수 있다. 한 페이지에당 5건의 데이터를 표시하도록 하면 첫번째 페이지에서는
LIMIT으로 5를 주면 된다. 그 다음 페이지에서는 6번째 행부터 5건의 데이터를 표시하도록 하면 된다.
이때 6번째 행부터라는 표현은 결괏값으로 데이터를 취득할 위치를 가리키는 것으로 LIMIT 구에 OFFSET을 지정할 수 있다.
SELECT * FROM testsql LIMIT 3 OFFSET 0;
첫 번째 행부터 세 번째 행까지 표시되었다. LIMIT 3으로 했을 때와 같은 결과이다. LIMIT구의 OFFSET은 생략 가능하며 기본값은 0이다.
OFFSET에 의한 시작 위치 지정은 LIMIT 뒤에 기술한다. 위치 지정은 0부터 시작하는 컴퓨터 자료구조 배열 인덱스를 떠올리면 조금이나마 이해하기 쉽다. 간단하게 정리하면 시작할 행 - 1로 기억해두면 편리하다.
예를 들어 첫번째 행부터 5건을 취득한다면 1 -1로 위치는 -이되어 OFFSET 0으로 지정하면 된다.
그럼 이번에는 두 번째 페이지를 표시한다고 가정하고 두 번째 페이지에는 4행부터 3건의 데이터를 표시해보자

현재 전체 리스트에서 4번째는 이렇게 22 , 21, 11 로 되어있는데
SELECT * FROM testsql LIMIT 3 OFFSET 3;
이렇게 작성하고 출력해주면

동일하게 출력이 되고 있다.
3이라고 썻지만 0, 1, 2, 3 순서이므로 4번째부터 나오게되서 4행부터 총 3개 4, 5, 6 행이 출력된 것이다.
이렇게 정렬에 대해 알아보았다. 4편부터는 연산을 알아보고 정리하도록 해보자!
여기까지 따라오신 분이 혹시라도 있다면 박수를 보내드린다.
모든 포스팅에 대한 내용은 도서 SQL첫걸음에서 익히고 배운 것들에 대한 내용을 직접 타이핑 하였음을 밝힙니다.
'BackEnd' 카테고리의 다른 글
| SQL 데이터베이스에 대해 제대로 알자(5) - 추가, 삭제, 갱신 (1) | 2023.03.09 |
|---|---|
| SQL 데이터베이스에 대해 제대로 알자(4) - 수치연산, CASE (0) | 2023.03.09 |
| SQL 데이터베이스에 대해 제대로 알자(2) - 조건조합하기,연산자 (0) | 2023.03.08 |
| SQL 데이터베이스에 대해 제대로 알자(1) - 데이터베이스란? (0) | 2023.03.08 |
| 접근제어자(Access Modifier) 무조건 이해하기 (0) | 2023.02.13 |